Source: examples/autoresearch
Parallel Autoresearch with SkyPilot#
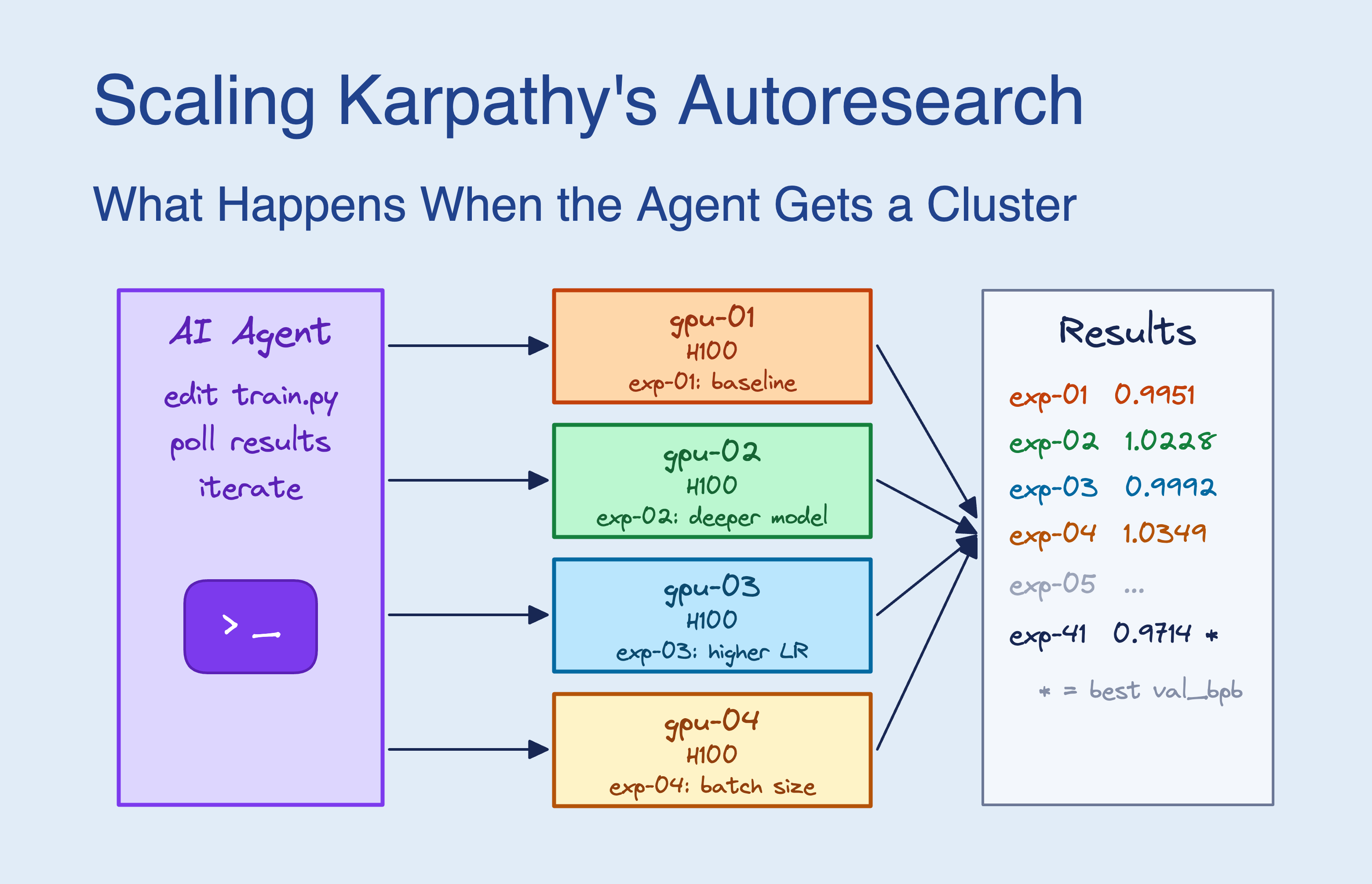
Run karpathy/autoresearch experiments in parallel on cloud GPUs using the SkyPilot skill. A local coding agent uses the skill to spin up GPU clusters, submit experiments, and parallelize work across multiple clusters.
For a deep dive into methodology and results, check out the blog post.
Architecture#
Local Agent (Claude Code, Codex, etc.)
|
|-- uses the SkyPilot skill to:
| - launch GPU clusters
| - submit experiment jobs (from experiment.yaml)
| - check job status and stream logs
| - SSH into clusters to inspect results
| - tear down idle clusters
|
|-- edits train.py with hypotheses
|-- tracks results in a local results.tsv
Agent runs locally, generates hypotheses, edits
train.pySkyPilot skill handles all infrastructure — the agent tells it what to do and the skill translates that into SkyPilot commands
SSH access — the agent SSHes into clusters to check experiment output directly
Files#
File |
Purpose |
|---|---|
|
SkyPilot task template: runs one experiment on a GPU cluster |
|
Agent instructions for using SkyPilot (give this to your coding agent) |
The original program.md from the autoresearch repo is fetched automatically during setup. It contains the experiment rules (what to modify, goals, constraints).
Prerequisites#
SkyPilot — Install following the SkyPilot installation guide.
Cloud credentials — Configure at least one cloud provider by running
sky check. See the cloud setup docs for details.
Quick Start#
# 1. Clone autoresearch
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch
# 2. Copy SkyPilot files into the repo
cp /path/to/this/example/experiment.yaml .
cp /path/to/this/example/instructions.md .
# 3. Prepare data
pip install uv && uv sync && uv run prepare.py
# 4. Install the SkyPilot skill for your agent
# See: https://docs.skypilot.co/en/latest/getting-started/skill.html
# 5. Tell your agent to start
# "Read instructions.md and start running parallel experiments"
The SkyPilot skill handles installation, credential setup, and all cluster operations. If SkyPilot isn’t installed yet, the skill will guide through that too.
Results#
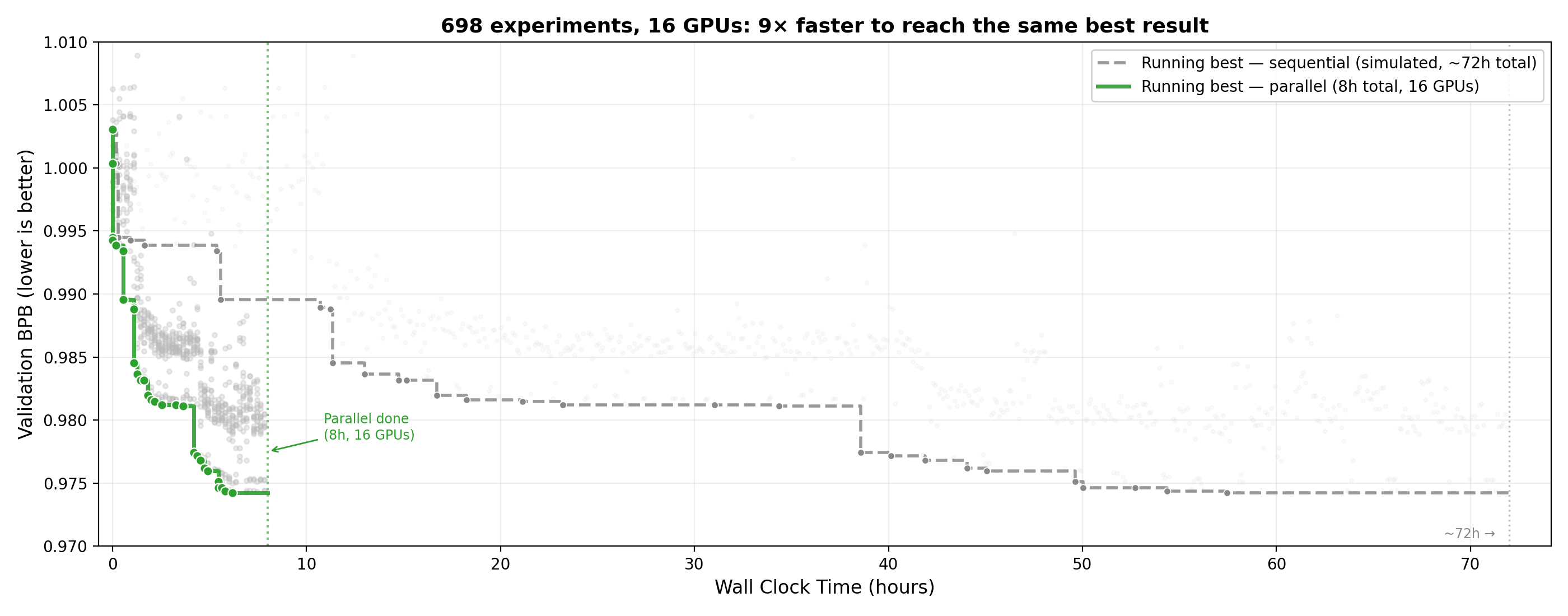
Parallel agent (16 GPUs) reaches the same best validation loss 9x faster than sequential (1 GPU).
In an 8-hour run across 16 GPUs, the parallel agent:
Submitted ~910 experiments (~90/hour vs ~10/hour sequential)
Achieved a 9x speedup to reach the same best validation loss
Improved val_bpb from 1.003 → 0.974 (2.87% improvement)
Cost: $9 in Claude API calls + $300 in GPU compute
Parallelism changes the agent’s search strategy. Instead of greedy sequential hill-climbing, it explores a grid — testing multiple hyperparameters simultaneously and cross-referencing results. The agent also independently discovered a two-tier strategy: screening hypotheses on cheaper H100s, then promoting winners to faster H200s, without being told to do so.
Included files#
experiment.yaml
resources:
accelerators: {H100:1, H200:1}
image_id: docker:nvcr.io/nvidia/pytorch:24.07-py3
workdir: .
envs:
EXPERIMENT_ID: baseline
EXPERIMENT_DESC: "baseline run"
setup: |
pip install uv
uv sync
uv run prepare.py
run: |
# Run the experiment (5-min fixed budget)
uv run train.py 2>&1 | tee run.log
EXIT_CODE=${PIPESTATUS[0]}
if [ $EXIT_CODE -ne 0 ]; then
echo "EXPERIMENT_STATUS: crash"
echo "Experiment ${EXPERIMENT_ID} crashed. Check logs above for details."
else
VAL_BPB=$(grep "^val_bpb:" run.log | awk '{print $2}')
PEAK_VRAM=$(grep "^peak_vram_mb:" run.log | awk '{print $2}')
if [ -z "$VAL_BPB" ] || [ -z "$PEAK_VRAM" ]; then
echo "EXPERIMENT_STATUS: crash"
echo "Experiment ${EXPERIMENT_ID} finished but failed to parse metrics from run.log."
else
MEMORY_GB=$(echo "scale=1; ${PEAK_VRAM} / 1024" | bc)
echo "EXPERIMENT_STATUS: done"
echo "EXPERIMENT_RESULT: ${EXPERIMENT_ID} val_bpb=${VAL_BPB} memory_gb=${MEMORY_GB}"
fi
fi
echo "EXPERIMENT_DESC: ${EXPERIMENT_DESC}"
Parallel Autoresearch with SkyPilot
You are an autonomous research agent running parallel GPU experiments via SkyPilot.
Setup
Read the autoresearch rules: Fetch and read program.md from the original repo. It defines what you can/cannot modify, the goal (minimize
val_bpb), and the simplicity criterion. Follow those rules.Load the SkyPilot skill: Fetch and follow the SkyPilot skill — run its “Before You Start” bootstrap to confirm SkyPilot is installed and credentials are configured.
Read the autoresearch codebase: Read
README.md,prepare.py, andtrain.pyfor full context.Ask about infra preference: Ask if the user prefers a specific cloud (e.g.
--infra nebius,--infra kubernetes). If so, setinfra:in the YAML. Otherwise SkyPilot picks the cheapest option.
Launching Experiments
Use the SkyPilot skill for all infrastructure operations. The template experiment.yaml defines a single experiment run. Name clusters gpu-01, gpu-02, etc. — each cluster can run multiple experiments over time.
Launch a cluster:
sky launch gpu-01 experiment.yaml --env EXPERIMENT_ID=exp-01 --env EXPERIMENT_DESC="baseline" -d -y
Pipeline experiments on the same cluster (back-to-back via the job queue):
sky exec gpu-01 experiment.yaml --env EXPERIMENT_ID=exp-02 --env EXPERIMENT_DESC="increase LR" -d
Workdir isolation: SkyPilot snapshots the working directory at submission time. To run different train.py variants in parallel, copy files to a per-experiment folder and use --workdir:
mkdir -p /tmp/autoresearch/exp-03
cp train.py prepare.py pyproject.toml experiment.yaml /tmp/autoresearch/exp-03/
# edit /tmp/autoresearch/exp-03/train.py
sky launch gpu-03 experiment.yaml --workdir /tmp/autoresearch/exp-03 --env EXPERIMENT_ID=exp-03 --env EXPERIMENT_DESC="wider model" -d -y
Keep at most 4 clusters running at a time.
Checking Results
Use sky logs to stream job output:
sky logs gpu-01 # latest job
sky logs gpu-01 2 # specific job ID
Or SSH in and inspect directly (workdir syncs to ~/sky_workdir):
ssh gpu-01
cd ~/sky_workdir
tail -20 run.log
Check status:
sky status # all clusters
sky queue gpu-01 # jobs on a specific cluster
Tracking Results
Maintain a local results.tsv (tab-separated):
experiment_id status val_bpb memory_gb description
exp-01 keep 0.997900 44.0 baseline
exp-02 discard 1.005000 44.0 switch to GeLU
exp-03 crash 0.000000 0.0 double width (OOM)
Status: keep (improvement), discard (no improvement), crash (failed).
The Experiment Loop
LOOP FOREVER:
Check state: Review
results.tsv,sky status,sky queue.Pick an untried idea.
Prepare: Copy code to a per-job folder, edit
train.py.Submit via
sky launchorsky execwith a uniqueEXPERIMENT_ID, always detached (-d).Don’t wait — move on to the next idea.
Periodically check results via
sky logsor SSH.val_bpbimproved → copy winningtrain.pyback, commit.Otherwise → log as
discard.
Tear down idle clusters:
sky down gpu-01 -yRepeat.
Timeout: If a run exceeds 10 minutes, treat as failure. Crashes: Check logs, fix trivial issues and resubmit, or log as crash.
NEVER STOP: Do NOT pause to ask the human if you should continue. Work indefinitely until manually stopped. If stuck, re-read the code, combine near-misses, try radical changes.
Cleanup
sky down -a -y
#!/usr/bin/env bash
set -euo pipefail
AUTORESEARCH_DIR="autoresearch"
EXAMPLES_BASE="https://raw.githubusercontent.com/skypilot-org/skypilot/master/examples/autoresearch"
echo "=== Autoresearch + SkyPilot setup ==="
echo ""
# 1. Install uv if missing
if ! command -v uv &>/dev/null; then
echo "[1/4] Installing uv..."
curl -LsSf https://astral.sh/uv/install.sh | sh
# uv's installer drops the binary here; make it available for the rest of this script
export PATH="${UV_TOOL_BIN_DIR:-$HOME/.local/bin}:$HOME/.cargo/bin:$PATH"
else
echo "[1/4] uv already installed ($(uv --version))"
fi
# 2. Install SkyPilot if missing
if ! command -v sky &>/dev/null; then
echo "[2/4] Installing SkyPilot via uv..."
uv tool install skypilot
export PATH="${UV_TOOL_BIN_DIR:-$HOME/.local/bin}:$HOME/.cargo/bin:$PATH"
else
echo "[2/4] SkyPilot already installed ($(sky --version 2>/dev/null || echo 'unknown version'))"
fi
# 3. Clone autoresearch
echo "[3/4] Cloning karpathy/autoresearch..."
if [ -d "$AUTORESEARCH_DIR" ]; then
echo " Directory '$AUTORESEARCH_DIR' already exists, skipping clone."
else
git clone https://github.com/karpathy/autoresearch.git "$AUTORESEARCH_DIR"
fi
# 4. Download SkyPilot files into the cloned repo
# (dependency installation and data prep are handled by experiment.yaml on the remote cluster)
echo "[4/4] Downloading experiment.yaml and instructions.md..."
curl -fsSL "$EXAMPLES_BASE/experiment.yaml" -o "$AUTORESEARCH_DIR/experiment.yaml"
curl -fsSL "$EXAMPLES_BASE/instructions.md" -o "$AUTORESEARCH_DIR/instructions.md"
echo ""
echo "=== Credential check ==="
# Capture sky check output without letting its exit code kill the script,
# then inspect the text. (sky check exits non-zero when some clouds are absent,
# which would otherwise trip set -e / pipefail on the pipe.)
SKY_CHECK=$(sky check 2>&1 || true)
if echo "$SKY_CHECK" | grep -q ": enabled"; then
echo "Cloud credentials OK."
else
echo ""
echo "No cloud credentials detected. Run 'sky check' to configure access."
echo "Docs: https://docs.skypilot.co/en/latest/getting-started/installation.html#cloud-account-setup"
echo ""
echo "You can still continue - SkyPilot will prompt you when you launch the first job."
fi
echo ""
echo "================================================================"
echo " Setup complete!"
echo "================================================================"
echo ""
echo " Change into the working directory first:"
echo ""
echo " cd $AUTORESEARCH_DIR"
echo ""
echo " Open Claude Code/Codex/any agent in this directory, then paste this prompt:"
echo ""
echo " Read instructions.md and start running parallel experiments."
echo ""
echo " To target a specific cloud, tell your agent:"
echo " '...set infra to aws' (or gcp, azure, kubernetes, etc.)"
echo ""
echo " Monitor clusters: sky status"
echo " Stream logs: sky logs <cluster-name>"
echo " Tear down all: sky down -a -y"
echo "================================================================"