High Availability Controller#
Overview#
This page describes high availability (HA) mode for remote controller clusters – the standalone VM or pod that SkyPilot launches to manage jobs or services.
Tip
Using a remote API server? For managed jobs, the API server manages jobs directly by default (see consolidation mode). The API server pod already has its own resilience (Kubernetes Deployment restarts, persistent database), so you do not need HA mode for managed jobs in that case.
HA mode is relevant when:
You have explicitly disabled consolidation mode (
consolidation_mode: false) and want a resilient remote jobs controller.You want a resilient Sky Serve controller (Sky Serve always uses a remote controller cluster).
By default, the controller for both Managed Jobs and Sky Serve runs as a single instance (either a VM or a Kubernetes Pod). If this instance fails due to node issues, pod crashes, or other unexpected events, the controller plane becomes unavailable, impacting service management capabilities until the controller is manually recovered or relaunched.
To enhance resilience and ensure controller plane continuity, we offer a high availability mode for the controller, which automatically recovers from failures.
High availability mode for the controller offers several key advantages:
Automated Recovery: The controller automatically restarts via Kubernetes Deployments if it encounters crashes or node failures.
Enhanced Control Plane Stability: Ensures the control plane remains operational with minimal disruption to management capabilities.
Persistent Controller State: Critical controller state is stored on persistent storage (via PVCs), ensuring it survives pod restarts and node failures.
Prerequisites#
Kubernetes Cluster: high availability mode is currently only supported when using Kubernetes as the cloud provider for the controller. You must have a Kubernetes cluster configured for SkyPilot. See Kubernetes Setup for details.
Persistent Kubernetes: The underlying Kubernetes cluster (control plane and nodes) must be running persistently. If using a local Kubernetes deployment (e.g., Minikube, Kind via
sky local up), the machine hosting the cluster must remain online.PersistentVolumeClaim (PVC) Support: The Kubernetes cluster must be able to provision PersistentVolumeClaims (e.g., via a default StorageClass or one specified in config.yaml), as these are required for storing the controller’s persistent state.
Permissions to create Deployments and PVCs: The user must have permissions to create Deployments and PVCs in the Kubernetes cluster. This is enabled by default for k8s clusters that are created by
sky local up, but on cloud managed k8s clusters, extra permission is required. For GKE, runkubectl apply -f ha-rbac.yamlon the following YAML:
# ha-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: skypilot-ha-controller-access
rules:
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["apps"]
resources: ["deployments", "deployments/status"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: skypilot-ha-controller-access
subjects:
- kind: ServiceAccount
name: skypilot-api-sa
namespace: skypilot
roleRef:
kind: ClusterRole
name: skypilot-ha-controller-access
apiGroup: rbac.authorization.k8s.io
Note
Currently, high availability mode is only supported for Kubernetes. Support for other clouds (e.g., AWS, GCP, Azure VMs) is under development (see GitHub PR #7032).
How to enable high availability mode#
To enable high availability for the controller, set the high_availability flag to true within the [jobs,serve].controller section of your SkyPilot configuration:
jobs:
controller:
consolidation_mode: false # Use a remote controller cluster (required for HA)
resources:
cloud: kubernetes # High availability mode requires Kubernetes
high_availability: true
serve:
controller:
resources:
cloud: kubernetes # High availability mode requires Kubernetes
high_availability: true
Note
For remote API servers, you must explicitly set consolidation_mode: false for managed jobs (as shown above) to use a remote controller cluster with HA mode. Without this, the API server manages jobs directly and the high_availability setting has no effect. This is not needed for the Sky Serve controller, which always uses a remote cluster.
Note
Enabling or disabling high_availability only affects new controllers. If you have an existing controller (either running or stopped), changing this setting will not modify it. To apply the change, you must first cancel all running jobs, or terminate all services, and then tear down the existing controller using sky down <controller-name>. See Important considerations below.
Note
While the controller requires Kubernetes for high availability mode, worker cluster for managed jobs and service replicas can still use any cloud or infrastructure supported by SkyPilot.
How it works#
When high_availability: true is set, SkyPilot modifies how the controller is deployed on Kubernetes:
The high availability implementation relies on standard Kubernetes mechanisms to ensure controller resilience:
Automatic Recovery: The controller runs as a Kubernetes Deployment that automatically restarts pods after failures.
Persistent State: Critical controller state (database, configuration) is stored on persistent storage that persists on pod restarts.
Seamless Continuation: When a new pod starts after a failure, it automatically reconnects to existing resources and continues operations without manual intervention.
Note
For Sky Serve, while the controller itself recovers automatically, the service endpoint availability is primarily managed by the load balancer. Currently, the load balancer runs alongside the controller. If the node hosting both fails, the service endpoint may experience a brief downtime during the recovery process. Decoupling the load balancer from the controller for even higher availability is under active development. Once decoupled, if the controller pod/node fails, an independently running load balancer could continue to hold incoming traffic and route it to healthy service replicas, further improving service endpoint uptime during controller failures.
The entire recovery process is handled transparently by SkyPilot and Kubernetes, requiring no action from users when failures occur.
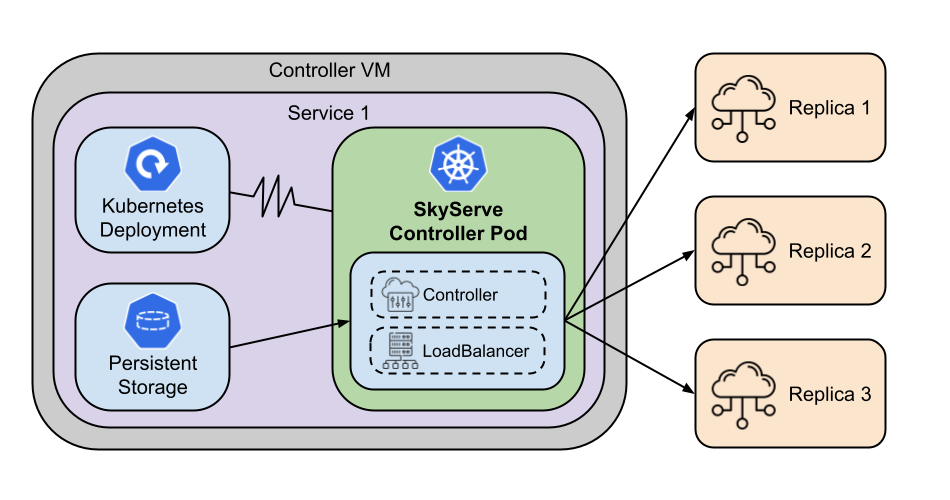
The high availability architecture for SkyServe.#
Configuration details#
Besides the main [jobs,serve].controller.high_availability: true flag, you can customize high availability behavior further:
Controller Resources (
[jobs,serve].controller.resources): As usual, you can specifycloud(must be Kubernetes for now),region,cpus, etc. Thedisk_sizehere directly determines the size of the PersistentVolumeClaim created for the high availability controller.For example, to set the controller’s disk size (which determines the PVC size in high availability mode when
[jobs,serve].controller.high_availabilityis true):jobs: controller: resources: disk_size: 100 # Example: 100Gi for the PVC cloud: kubernetes # Must be kubernetes for HA controller # cpus: 2+ # Other optional resources high_availability: true # Must be true for HA mode
Kubernetes Storage Class (
kubernetes.high_availability.storage_class_name- Optional): If your Kubernetes cluster has specific storage classes defined (e.g., for different performance tiers like SSD vs HDD, or specific features like backup), you can specify which one to use for the controller’s PVC. Note: This is configured under thekubernetessection inconfig.yaml, not as a top-levelhigh_availabilitysection.To specify a storage class for the controller’s PVC:
kubernetes: # ... other kubernetes settings ... high_availability: # Optional: Specify the StorageClass name for the controller's PVC storage_class_name: <your-storage-class-name> # e.g., premium-ssd
Note
Different storage classes offer varying performance (IOPS, throughput), features (snapshots, backups), and costs. If your cluster provides multiple options and you have specific requirements for the controller’s storage (e.g., needing faster disk I/O or a particular backup strategy), you can specify a storage class. If omitted, the default storage class configured in your Kubernetes cluster will be used.
Important considerations#
Currently Kubernetes Only: This feature relies entirely on Kubernetes mechanisms (Deployments, PVCs) and is only available when the controller’s specified
cloudiskubernetes. Support for other clouds (AWS, GCP, Azure VMs) is under development.Persistent K8s Required: The high availability mechanism depends on the Kubernetes cluster itself being available. Ensure your K8s control plane and nodes are stable.
No Effect on Existing Controllers: Setting
high_availability: trueinconfig.yamlwill not convert an existing non-high availability controller (running or stopped) to high availability mode, nor will setting it tofalseconvert an existing high availability controller to non-high availability. You must tear down the existing controller first (sky down <controller-name>after terminating all services) for the new setting to apply when the controller is next launched.Inconsistent State Error: If you attempt to submit a new job (
sky jobs launch) or launch a service (sky serve up) and thehigh_availabilitysetting in yourconfig.yamlconflicts with the actual state of the existing controller cluster on Kubernetes (e.g., you enabled high availability in config, but the controller exists as a non-high availability Pod, or vice-versa), SkyPilot will raise anInconsistentHighAvailabilityError. To resolve this, cancel all running jobs or terminate all services, tear down the controller (sky down <controller-name>), and then runsky jobs launchorsky serve upagain with the desired consistent configuration.
Recovery example for SkyServe#
This example demonstrates the automatic recovery capability of the high availability controller for Sky Serve:
Preparatory Steps (Ensure Clean State & Correct Config):
Terminate Existing Controller (if any):
First, ensure no services are running. Terminate them with
sky serve down <service_name>orsky serve down --all.Find the controller name:
sky status | grep sky-serve-controller
Terminate and purge the controller (replace
<sky-serve-controller-name>with the name you found above):sky down <sky-serve-controller-name>
Set Configuration: First, ensure your
~/.sky/config.yamlenables high availability mode as shown in the How to enable high availability mode section.~/.sky/config.yaml (relevant part)#serve: controller: resources: cloud: kubernetes high_availability: true
Prepare Configuration Files:
Service Definition (e.g.,
http_service.yaml): Use a simple HTTP service.http_service.yaml#service: readiness_probe: / # Default path for http.server replicas: 1 resources: ports: 8080 cpus: 1 # Minimal resources run: python3 -m http.server 8080 --bind 0.0.0.0
You can also use the
http_server.yamlfrom the examples/serve/http_server/task.yaml file.
Launch the Service:
sky serve up -n my-http-service http_service.yaml # This will launch the new high availability controller based on your config.
Wait and Verify the Service: Wait until the service status becomes
READY.watch sky serve status my-http-service # Wait for STATUS to become READY # Get the endpoint URL ENDPOINT=$(sky serve status my-http-service --endpoint) echo "Service endpoint: $ENDPOINT" # Verify the service is rnvesponding correctly curl $ENDPOINT # Should see the default HTML output from http.server
Simulate Controller Failure (Manually Delete Pod):
Find the name of the controller pod. Controller pods typically contain “sky-serve-controller” and have the label
skypilot-head-node=1.kubectl get pods -l skypilot-head-node=1 | grep sky-serve-controller # Copy the controller pod name (e.g., sky-serve-controller-deployment-xxxxx-yyyyy) CONTROLLER_POD=<paste_controller_pod_name_here>
Delete the controller pod.
echo "Deleting controller pod: $CONTROLLER_POD" kubectl delete pod $CONTROLLER_POD
Observe Recovery: The Kubernetes Deployment will detect the missing pod and automatically create a new one to replace it.
echo "Waiting for controller pod to recover..." # Wait a few seconds for Kubernetes to react sleep 15 # Check that a new pod has started and is running (Status should be Running 1/1) kubectl get pods -l skypilot-head-node=1 # Note the pod name will be different, and STATUS should be Running
Verify Service Again: Even though the controller pod was restarted, the service endpoint should remains the same and still be accessible (there might be a brief interruption depending on load balancer and K8s response times).
echo "Re-checking service endpoint: $ENDPOINT" curl $ENDPOINT # Should still see the http.server output, indicating the service has recovered
This example shows that even if the controller pod terminates unexpectedly, the Kubernetes Deployment mechanism automatically restores it, and thanks to the persisted state (via PVC) and recovery logic, the service continues to operate.