Source: llm/yi
Running Yi with SkyPilot on Your Cloud#
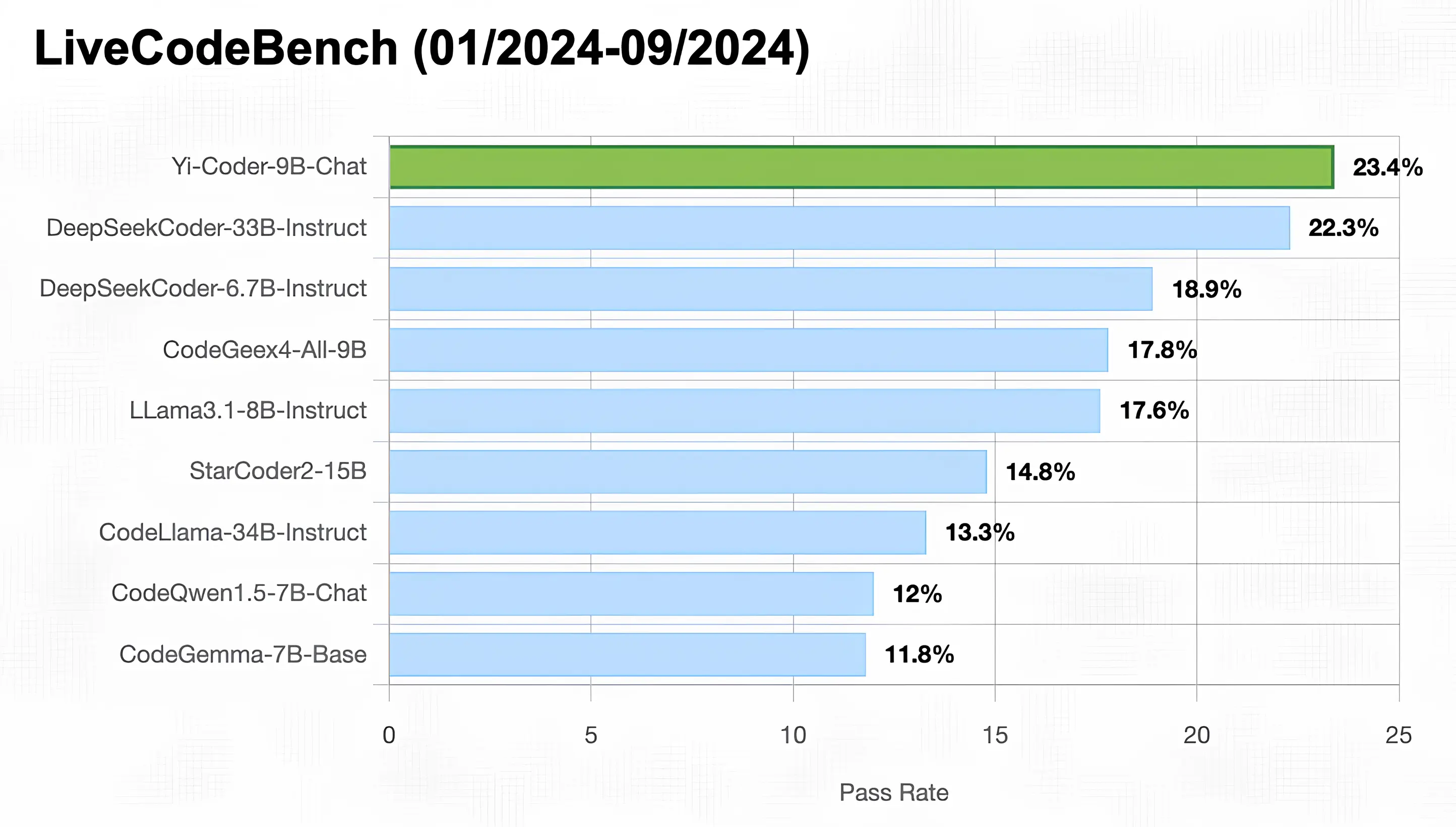
🤖 The Yi series models are the next generation of open-source large language models trained from scratch by 01.AI.
Update (Sep 19, 2024) - SkyPilot now supports the Yi model(Yi-Coder Yi-1.5)!
Why use SkyPilot to deploy over commercial hosted solutions?#
Get the best GPU availability by utilizing multiple resources pools across Kubernetes clusters and multiple regions/clouds.
Pay absolute minimum — SkyPilot picks the cheapest resources across Kubernetes clusters and regions/clouds. No managed solution markups.
Scale up to multiple replicas across different locations and accelerators, all served with a single endpoint
Everything stays in your Kubernetes or cloud account (your VMs & buckets)
Completely private - no one else sees your chat history
Running Yi model with SkyPilot#
After installing SkyPilot, run your own Yi model on vLLM with SkyPilot in 1-click:
Start serving Yi-1.5 34B on a single instance with any available GPU in the list specified in yi15-34b.yaml with a vLLM powered OpenAI-compatible endpoint (You can also switch to yicoder-9b.yaml or other model for a smaller model):
sky launch -c yi yi15-34b.yaml
Send a request to the endpoint for completion:
ENDPOINT=$(sky status --endpoint 8000 yi)
curl http://$ENDPOINT/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "01-ai/Yi-1.5-34B-Chat",
"prompt": "Who are you?",
"max_tokens": 512
}' | jq -r '.choices[0].text'
Send a request for chat completion:
curl http://$ENDPOINT/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "01-ai/Yi-1.5-34B-Chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Who are you?"
}
],
"max_tokens": 512
}' | jq -r '.choices[0].message.content'
Included files#
yi15-34b.yaml
envs:
MODEL_NAME: 01-ai/Yi-1.5-34B-Chat
resources:
accelerators: {A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
disk_size: 1024
disk_tier: best
memory: 32+
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yi15-6b.yaml
envs:
MODEL_NAME: 01-ai/Yi-1.5-6B-Chat
resources:
accelerators: {L4, A10g, A10, L40, A40, A100, A100-80GB}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yi15-9b.yaml
envs:
MODEL_NAME: 01-ai/Yi-1.5-9B-Chat
resources:
accelerators: {L4:8, A10g:8, A10:8, A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yicoder-1_5b.yaml
envs:
MODEL_NAME: 01-ai/Yi-Coder-1.5B-Chat
resources:
accelerators: {L4, A10g, A10, L40, A40, A100, A100-80GB}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yicoder-9b.yaml
envs:
MODEL_NAME: 01-ai/Yi-Coder-9B-Chat
resources:
accelerators: {L4:8, A10g:8, A10:8, A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log