Quickstart#
This guide will walk you through:
Defining a task in a simple YAML format
Provisioning a cluster and running a task
Using the core SkyPilot CLI commands
Be sure to complete the installation instructions first before continuing with this guide.
Hello, SkyPilot!#
Let’s define our very first task, a simple Hello, SkyPilot! program.
Create a directory from anywhere on your machine:
$ mkdir hello-sky
$ cd hello-sky
Copy the following YAML into a hello_sky.yaml file:
resources:
# Optional; if left out, automatically pick the cheapest cloud.
infra: k8s/coreweave # Or k8s/my-neocloud; aws; gcp; ...
# 8x NVIDIA B200 GPU
accelerators: B200:8
# Working directory (optional) containing the project codebase.
# Its contents are synced to ~/sky_workdir/ on the cluster.
workdir: .
# Typical use: pip install -r requirements.txt
# Invoked under the workdir (i.e., can use its files).
setup: |
uv pip install torch
# Typical use: make use of resources, such as running training.
# Invoked under the workdir (i.e., can use its files).
run: |
echo "Hello, SkyPilot!"
nvidia-smi
Copy the following Python script to a hello_sky.py file:
import sky
import sys
# List of commands to run
commands = [
'echo "Hello, SkyPilot!"',
'nvidia-smi'
]
# Define a resource object.
# infra: (Optional) if left out, automatically pick cheapest available.
# accelerators: 8x NVIDIA B200 GPU
resource = sky.Resources(infra='k8s/coreweave', accelerators='B200:8') # Or 'k8s/my-neocloud', 'aws', 'gcp', ...
# Define a task object.
# setup: Typical use: pip install -r requirements.txt
# run: Typical use: make use of resources, such as running training.
# workdir: Working directory (optional) containing the project codebase.
# Its contents are synced to ~/sky_workdir/ on the cluster.
# Both `setup` and `run` is invoked under the workdir (i.e., can use its files).
task = sky.Task(setup='uv pip install torch',
run=commands,
workdir='.',
resources=resource)
# Launch the task.
request_id = sky.launch(task=task, cluster_name='mycluster')
# (Optional) stream the logs from the task to the console.
job_id, handle = sky.stream_and_get(request_id)
cluster_name = handle.get_cluster_name()
returncode = sky.tail_logs(cluster_name, job_id, follow=True)
sys.exit(returncode)
Tip
You can use the cluster_name parameter to give the cluster an easy-to-remember name. If not specified, a name is autogenerated.
If the cluster name is an existing cluster shown in sky status, the cluster will be reused.
Tip
Setup/run commands can get complicated when using if statements, for loops, etc. For this, we support using textwrap.dedent for multi-line commands.
import sky
import textwrap
commands = textwrap.dedent("""\
for i in {1..5}; do
echo "Hello, SkyPilot!"
done
nvidia-smi
""")
task = sky.Task(run=commands)
This defines a task with the following components:
resources: cloud resources the task must be run on (e.g., accelerators, instance type, etc.)workdir: the working directory containing project code that will be synced to the provisioned instance(s)setup: commands that must be run before the task is executed (invoked under workdir)run: commands that run the actual task (invoked under workdir)
All these fields are optional.
Now we can launch a cluster to run a task:
Use sky launch:
$ sky launch -c mycluster hello_sky.yaml
Tip
You can use the -c flag to give the cluster an easy-to-remember name. If not specified, a name is autogenerated.
If the cluster name is an existing cluster shown in sky status, the cluster will be reused.
Run the python script:
$ python hello_sky.py
Tip
This may take a few minutes for the first run. Feel free to read ahead on this guide.
By launching, SkyPilot performs much of the heavy-lifting:
selects an appropriate cloud and VM based on the specified resource constraints;
provisions (or reuses) a cluster on that cloud;
syncs up the
workdir;executes the
setupcommands; andexecutes the
runcommands.
In a few minutes, the cluster will finish provisioning and the task will be executed.
The outputs will show Hello, SkyPilot! and the list of installed Conda environments.
Execute a task on an existing cluster#
Instead of launching a new cluster every time, we can execute tasks on an existing cluster:
Using sky exec:
$ sky exec mycluster hello_sky.yaml
Tip
Bash commands are also supported, such as:
$ sky exec mycluster python train_cpu.py
$ sky exec mycluster --gpus=B200:8 python train_gpu.py
For interactive/monitoring commands, such as htop or gpustat -i, use ssh instead (see below) to avoid job submission overheads.
Using Python:
import sky
import sys
# Super simple task to run on a SkyPilot cluster.
task = sky.Task(run='echo "Hello, SkyPilot!"')
# Execute the task. Remember we launched `mycluster` before?
request_id = sky.exec(task, cluster_name='mycluster')
# (Optional) stream the logs from the task to the console.
job_id, handle = sky.stream_and_get(request_id)
cluster_name = handle.get_cluster_name()
returncode = sky.tail_logs(cluster_name, job_id, follow=True)
sys.exit(returncode)
The executing tasks on an existing cluster is more lightweight; it
syncs up the
workdir(so that the task may use updated code); andexecutes the
runcommands.
Provisioning and setup commands are skipped.
View all clusters#
Use sky status to see all clusters (across regions and clouds) in a single table:
$ sky status
This may show multiple clusters, if you have created several:
NAME INFRA RESOURCES STATUS AUTOSTOP LAUNCHED
mygcp GCP (us-central1-a) 1x(cpus=4, mem=16, n2-standard-4, ...) STOPPED - 1 day ago
mycluster Kubernetes (coreweave) 1x(gpus=B200:8, ...) UP - 4 mins ago
See here for a list of all possible cluster states.
Access the dashboard#
SkyPilot offers a dashboard for all clusters and jobs launched with SkyPilot. To open the dashboard, run sky dashboard, which will automatically opens a browser tab for the dashboard.
Start dashboard when installing SkyPilot from source
If you install SkyPilot from source, before starting the API server:
Run the following commands to generate the dashboard build:
# Install all dependencies
$ npm --prefix sky/dashboard install
# Build
$ npm --prefix sky/dashboard run build
Start the dashboard with
sky dashboard.
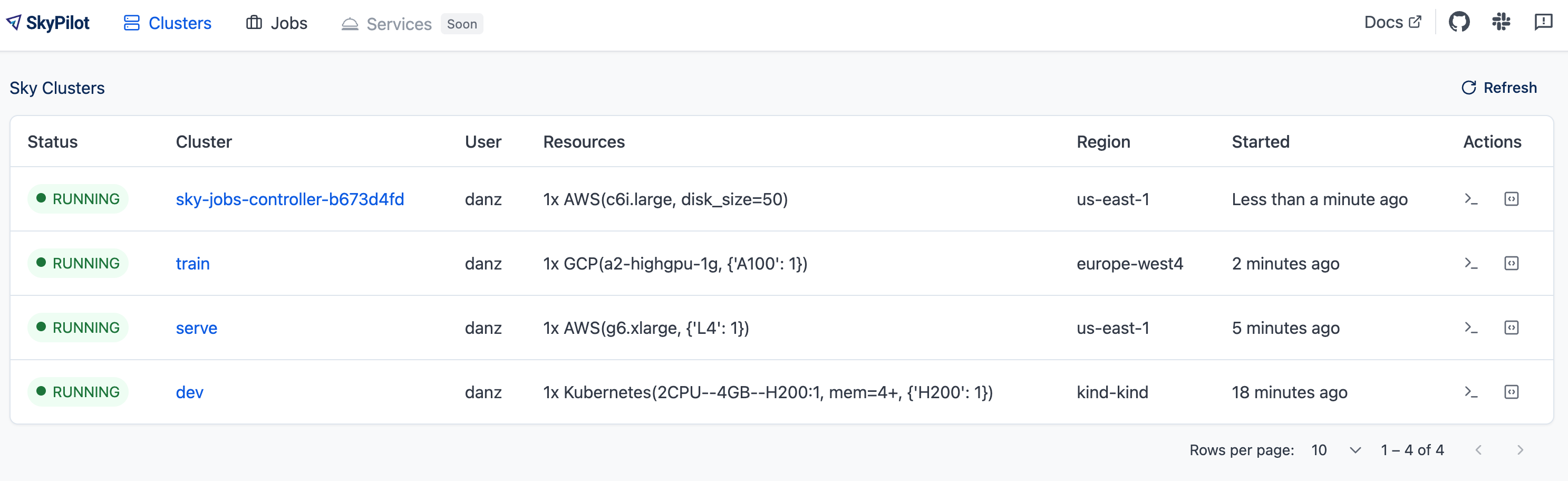
The clusters page example:
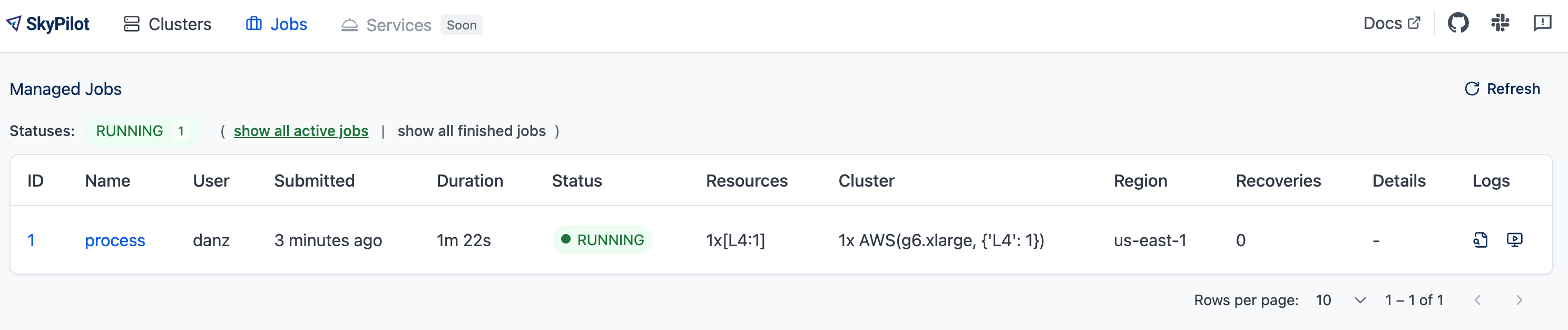
The managed jobs page example:
SSH into clusters#
Simply run ssh <cluster_name> to log into a cluster:
$ ssh mycluster
Multi-node clusters work too:
# Assuming 3 nodes.
# Head node.
$ ssh mycluster
# Worker nodes.
$ ssh mycluster-worker1
$ ssh mycluster-worker2
The above are achieved by adding appropriate entries to ~/.ssh/config.
Because SkyPilot exposes SSH access to clusters, this means clusters can be easily used inside tools such as Visual Studio Code Remote.
Transfer files#
After a task’s execution, use rsync or scp to download files (e.g., checkpoints):
$ rsync -Pavz mycluster:/remote/source /local/dest # copy from remote VM
For uploading files to the cluster, see Syncing Code and Artifacts.
Stop/terminate a cluster#
When you are done, stop the cluster:
Using sky stop:
$ sky stop mycluster
Using python:
import sky
request_id = sky.stop('mycluster')
# (Optional) Wait for `sky stop` to finish.
sky.stream_and_get(request_id)
Otherwise, terminate the cluster:
Using sky down:
$ sky down mycluster
Using python:
import sky
request_id = sky.down('mycluster')
# (Optional) Wait for `sky down` to finish.
sky.stream_and_get(request_id)
Note
Stopping a cluster does not lose data on the attached disks (billing for the instances will stop while the disks will still be charged). Those disks will be reattached when restarting the cluster.
Terminating a cluster will delete all associated resources (all billing stops), and any data on the attached disks will be lost. Terminated clusters cannot be restarted.
Find more commands that manage the lifecycle of clusters in the CLI reference and SDK reference.
Scaling out#
So far, we have used SkyPilot’s CLI to submit work to and interact with a single cluster. When you are ready to scale out (e.g., run 10s, 100s, or 1000s of jobs), use managed jobs to run on auto-managed clusters.
Using sky jobs launch:
$ for i in $(seq 100) # launch 100 jobs
do sky jobs launch --detach-run --async --yes -n hello-$i hello_sky.yaml
done
Using python:
import sky
from sky import jobs as managed_jobs
for i in range(100):
resource = sky.Resources(use_spot=True)
task = sky.Task(resources=resource, run='echo "Hello, SkyPilot!"')
managed_jobs.launch(task, name=f'hello-{i}')
After you launch the jobs, open the SkyPilot dashboard and check job status(es) in the Jobs tab.
$ sky dashboard # check the job status in Jobs tab.
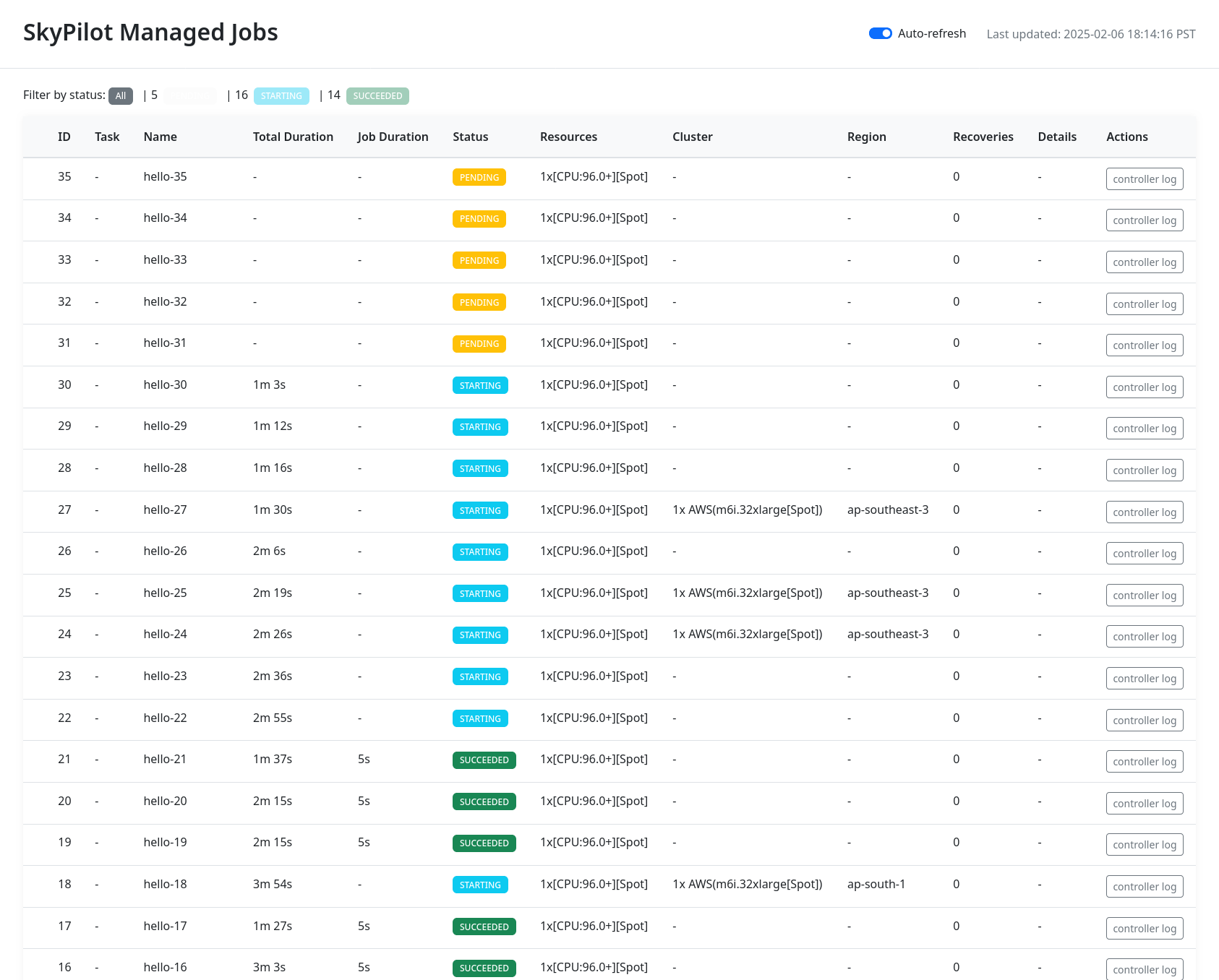
SkyPilot can support thousands of managed jobs running at once.
Asynchronous execution#
All SkyPilot CLIs and APIs are asynchronous requests, i.e. you can interrupt them at
any time and let them run in the background. For example, if you KeyInterrupt the sky launch command,
the cluster will keep provisioning in the background:
$ sky launch -c mycluster hello_sky.yaml
^C
⚙︎ Request will continue running asynchronously.
├── View logs: sky api logs 73d316ac
├── Or, visit: http://127.0.0.1:46580/api/stream?request_id=73d316ac
└── To cancel the request, run: sky api cancel 73d316ac
See more details in Asynchronous Execution.
Next steps#
Congratulations! In this quickstart, you have launched a cluster, run a task, and interacted with SkyPilot’s CLI.
Next steps:
Adapt Tutorial: AI Training to start running your own project on SkyPilot!
See the Task YAML reference, CLI reference, and more examples.
Set up SkyPilot for a multi-user team: Team Deployment.
Install SkyPilot Skill for your AI agents.
We invite you to explore SkyPilot’s unique features in the rest of the documentation.