
Managed Spot Jobs#
Tip
This feature is great for scaling out: running a single job for long durations, or running many jobs.
SkyPilot supports managed spot jobs that can automatically recover from preemptions. This feature saves significant cost (e.g., up to 70% for GPU VMs) by making preemptible spot instances practical for long-running jobs.
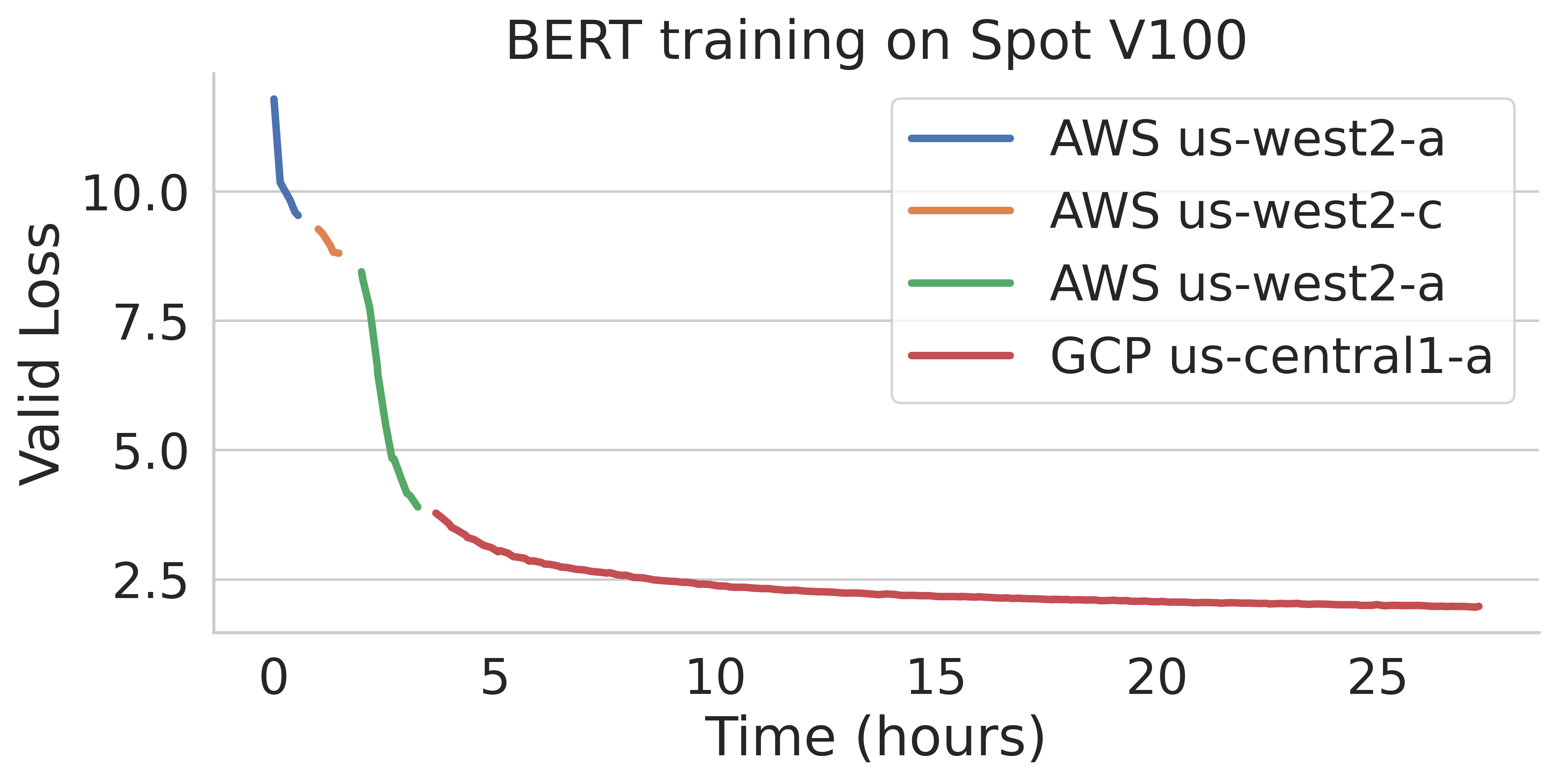
SkyPilot automatically finds available spot resources across regions and clouds to maximize availability. Here is an example of a BERT training job failing over different regions across AWS and GCP.

To use managed spot jobs, there are two requirements:
Task YAML: Managed Spot requires a YAML to describe the job, tested with
sky launch.Checkpointing (optional): For job recovery due to preemptions, the user application code can checkpoint its progress periodically to a mounted cloud bucket. The program can reload the latest checkpoint when restarted.
Task YAML#
To launch a spot job, you can simply reuse your task YAML (recommended to test it with sky launch first).
For example, we found the BERT fine-tuning YAML works with sky launch, and want to
launch it with SkyPilot managed spot jobs.
We can launch it with the following:
$ sky spot launch -n bert-qa bert_qa.yaml
# bert_qa.yaml
name: bert_qa
resources:
accelerators: V100:1
# Assume your working directory is under `~/transformers`.
# To make this example work, please run the following command:
# git clone https://github.com/huggingface/transformers.git ~/transformers -b v4.30.1
workdir: ~/transformers
setup: |
# Fill in your wandb key: copy from https://wandb.ai/authorize
# Alternatively, you can use `--env WANDB_API_KEY=$WANDB_API_KEY`
# to pass the key in the command line, during `sky spot launch`.
echo export WANDB_API_KEY=[YOUR-WANDB-API-KEY] >> ~/.bashrc
pip install -e .
cd examples/pytorch/question-answering/
pip install -r requirements.txt torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install wandb
run: |
cd ./examples/pytorch/question-answering/
python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 50 \
--max_seq_length 384 \
--doc_stride 128 \
--report_to wandb
Note
workdir and file mounts with local files will be automatically uploaded to a cloud bucket. The bucket will be created during the job running time, and cleaned up after the job finishes.
SkyPilot will launch and start monitoring the spot job. When a preemption happens, SkyPilot will automatically search for resources across regions and clouds to re-launch the job.
In this example, the job will be restarted from scratch after each preemption recovery. To resume the job from previous states, user’s application needs to implement checkpointing and recovery.
Checkpointing and recovery#
To allow spot recovery, a cloud bucket is typically needed to store the job’s states (e.g., model checkpoints).
Below is an example of mounting a bucket to /checkpoint.
file_mounts:
/checkpoint:
name: # NOTE: Fill in your bucket name
mode: MOUNT
The MOUNT mode in SkyPilot bucket mounting ensures the checkpoints outputted to /checkpoint are automatically synced to a persistent bucket.
Note that the application code should save program checkpoints periodically and reload those states when the job is restarted.
This is typically achieved by reloading the latest checkpoint at the beginning of your program.
An end-to-end example#
Below we show an example for fine-tuning a BERT model on a question-answering task with HuggingFace.
# bert_qa.yaml
name: bert_qa
resources:
accelerators: V100:1
# Assume your working directory is under `~/transformers`.
# To make this example work, please run the following command:
# git clone https://github.com/huggingface/transformers.git ~/transformers -b v4.30.1
workdir: ~/transformers
file_mounts:
/checkpoint:
name: # NOTE: Fill in your bucket name
mode: MOUNT
setup: |
# Fill in your wandb key: copy from https://wandb.ai/authorize
# Alternatively, you can use `--env WANDB_API_KEY=$WANDB_API_KEY`
# to pass the key in the command line, during `sky spot launch`.
echo export WANDB_API_KEY=[YOUR-WANDB-API-KEY] >> ~/.bashrc
pip install -e .
cd examples/pytorch/question-answering/
pip install -r requirements.txt
pip install wandb
run: |
cd ./examples/pytorch/question-answering/
python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 50 \
--max_seq_length 384 \
--doc_stride 128 \
--report_to wandb \
--run_name $SKYPILOT_TASK_ID \
--output_dir /checkpoint/bert_qa/ \
--save_total_limit 10 \
--save_steps 1000
As HuggingFace has built-in support for periodically checkpointing, we only need to pass the highlighted arguments for setting up the output directory and frequency of checkpointing (see more on Huggingface API). You may also refer to another example here for periodically checkpointing with PyTorch.
We also set --run_name to $SKYPILOT_TASK_ID so that the logs for all recoveries of the same job will be saved
to the same run in Weights & Biases.
Note
The environment variable $SKYPILOT_TASK_ID (example: “sky-2022-10-06-05-17-09-750781_spot_id-22”) can be used to identify the same job, i.e., it is kept identical across all
recoveries of the job.
It can be accessed in the task’s run commands or directly in the program itself (e.g., access
via os.environ and pass to Weights & Biases for tracking purposes in your training script). It is made available to
the task whenever it is invoked.
With the highlighted changes, the managed spot job can now resume training after preemption with sky spot launch! We can enjoy the benefits of
cost savings from spot instances without worrying about preemption or losing progress.
$ sky spot launch -n bert-qa bert_qa.yaml
Tip
Try copy-paste this example and adapt it to your own job.
Useful CLIs#
Here are some commands for managed spot jobs. Check sky spot --help for more details.
See all spot jobs:
$ sky spot queue
Fetching managed spot job statuses...
Managed spot jobs:
ID NAME RESOURCES SUBMITTED TOT. DURATION JOB DURATION #RECOVERIES STATUS
2 roberta 1x [A100:8] 2 hrs ago 2h 47m 18s 2h 36m 18s 0 RUNNING
1 bert-qa 1x [V100:1] 4 hrs ago 4h 24m 26s 4h 17m 54s 0 RUNNING
Stream the logs of a running spot job:
$ sky spot logs -n bert-qa # by name
$ sky spot logs 2 # by job ID
Cancel a spot job:
$ sky spot cancel -n bert-qa # by name
$ sky spot cancel 2 # by job ID
Note
If any failure happens for a spot job, you can check sky spot queue -a for the brief reason
of the failure. For more details, it would be helpful to check sky spot logs --controller <job_id>.
Dashboard#
Use sky spot dashboard to open a dashboard to see all jobs:
$ sky spot dashboard
This automatically opens a browser tab to show the dashboard:
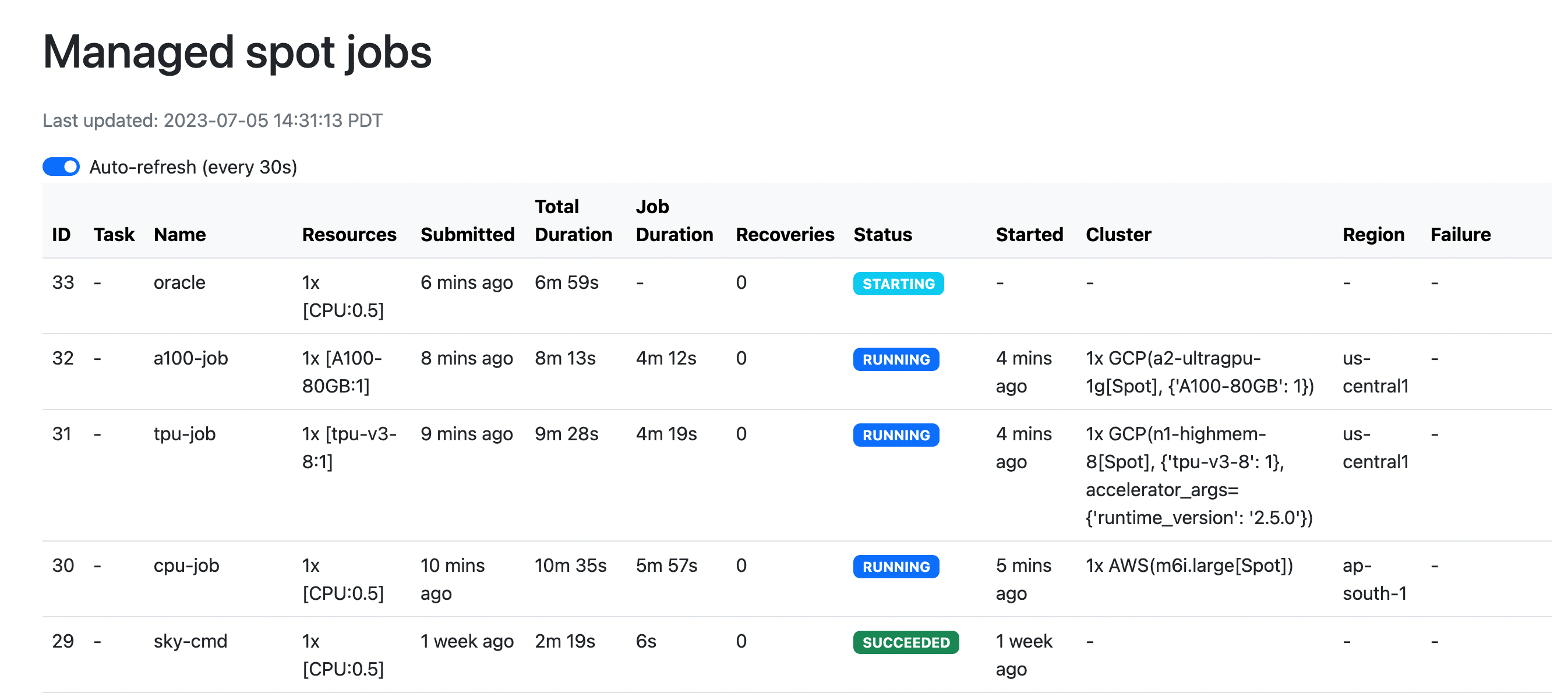
The UI shows the same information as the CLI sky spot queue -a. The UI is
especially useful when there are many in-progress jobs to monitor, which the
terminal-based CLI may need more than one page to display.
Real-world examples#
Spot controller#
The spot controller is a small on-demand CPU VM running in the cloud that manages all spot jobs of a user. It is automatically launched when the first managed spot job is submitted, and it is autostopped after it has been idle for 10 minutes (i.e., after all spot jobs finish and no new spot job is submitted in that duration). Thus, no user action is needed to manage its lifecycle.
You can see the controller with sky status and refresh its status by using the -r/--refresh flag.
While the cost of the spot controller is negligible (~$0.4/hour when running and less than $0.004/hour when stopped),
you can still tear it down manually with
sky down <spot-controller-name>, where the <spot-controller-name> can be found in the output of sky status.
Note
Tearing down the spot controller loses all logs and status information for the finished spot jobs. It is only allowed when there are no in-progress spot jobs to ensure no resource leakage.
Customizing spot controller resources#
You may want to customize the resources of the spot controller for several reasons:
Use a lower-cost controller (if you have a low number of concurrent spot jobs).
Enforcing the spot controller to run on a specific location. (Default: cheapest location)
Changing the maximum number of spot jobs that can be run concurrently, which is 2x the vCPUs of the controller. (Default: 16)
Changing the disk_size of the spot controller to store more logs. (Default: 50GB)
To achieve the above, you can specify custom configs in ~/.sky/config.yaml with the following fields:
spot:
# NOTE: these settings only take effect for a new spot controller, not if
# you have an existing one.
controller:
resources:
# All configs below are optional.
# Specify the location of the spot controller.
cloud: gcp
region: us-central1
# Specify the maximum number of spot jobs that can be run concurrently.
cpus: 4+ # number of vCPUs, max concurrent spot jobs = 2 * cpus
# Specify the disk_size in GB of the spot controller.
disk_size: 100
The resources field has the same spec as a normal SkyPilot job; see here.
Note
These settings will not take effect if you have an existing controller (either stopped or live). For them to take effect, tear down the existing controller first, which requires all in-progress spot jobs to finish or be canceled.
Spot Pipeline#
Spot Pipeline is a feature that allows you to submit a spot job that contains a sequence of spot tasks running one after another. This is useful for running a sequence of jobs that depend on each other, e.g., training a model and then running inference on it. This allows the multiple tasks to have different resource requirements to fully utilize the resources and save cost, while keeping the burden of managing the tasks off the user.
Note
A spot job is either a single task or a pipeline of tasks. A spot job is submitted by sky spot launch.
All tasks in a pipeline will be run on spot instances.
To use Spot Pipeline, you can specify the sequence of jobs in a YAML file. Here is an example:
name: pipeline
---
name: train
resources:
accelerators: V100:8
file_mounts:
/checkpoint:
name: train-eval # NOTE: Fill in your bucket name
mode: MOUNT
setup: |
echo setup for training
run: |
echo run for training
echo save checkpoints to /checkpoint
---
name: eval
resources:
accelerators: T4:1
file_mounts:
/checkpoint:
name: train-eval # NOTE: Fill in your bucket name
mode: MOUNT
setup: |
echo setup for eval
run: |
echo load trained model from /checkpoint
echo eval model on test set
The above YAML file defines a pipeline with two tasks. The first name: pipeline names the pipeline. The first task has name train and the second task has name eval. The tasks are separated by a line with three dashes ---. Each task has its own resources, setup, and run sections. The setup and run sections are executed sequentially.
To submit the pipeline, the same command sky spot launch is used. The pipeline will be automatically launched and monitored by SkyPilot. You can check the status of the pipeline with sky spot queue or sky spot dashboard.
$ sky spot launch -n pipeline pipeline.yaml
$ sky spot queue
Fetching managed spot job statuses...
Managed spot jobs
In progress tasks: 1 PENDING, 1 RECOVERING
ID TASK NAME RESOURCES SUBMITTED TOT. DURATION JOB DURATION #RECOVERIES STATUS
8 pipeline - 50 mins ago 47m 45s - 1 RECOVERING
↳ 0 train 1x [V100:8] 50 mins ago 47m 45s - 1 RECOVERING
↳ 1 eval 1x [T4:1] - - - 0 PENDING